논문의 목표 : 자율주행 분야에서 single monocular image를 이용하여 3D object detection을 수행하는 알고리즘을 제안한다.
Introduction
본 논문에서는 여러 정보를 이용하여 매우 높은 재현율(recall)로 class-specific한 3D object proposal generation 방법을 제안한다.
semantic and object instance segmentation, context 뿐만아니라 shape features 와 location prior을 이용하여 box scoring을 수행한다.
Monocular 3D Object Detection
이 논문에서는 이미지의 segmentation, context 뿐만아니라 location prior를 이용하여 더 정확한 3D object detection을 수행하는 방법을 제시한다.
또한, 대부분의 물체는 바닥에 가깝거나 놓여있으므로 ground plane을 이용한다.
we do not force it, only encourage them to be close.
-Generating 3D Object Proposal
3D bounding box = (x, y, z, θ, c, t). ( (x, y, z)center of the 3D box, θ azimuth angle, c object class)
training data로 부터 class 별 bounding box 크기 (3D templates t)를 학습한다.

semantic segmentation
첫번째 feature는 2D bounding box 안에 해당하는 클래스의 픽셀이 얼마나 속해있는지를 계산한다.
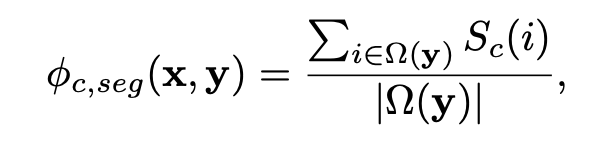
Ω(y) : 3D bounding box를 2D 이미지에 projection 시켜 얻은 2D box 안에 있는 pixel의 집합.
Sc : c 클래스에 해당하는 segmentation mask.
두번째 feature는 위와 반대로 해당 클래스를 제외한 다른 클래스의 픽셀이 얼마나 속해있는지 계산한다.
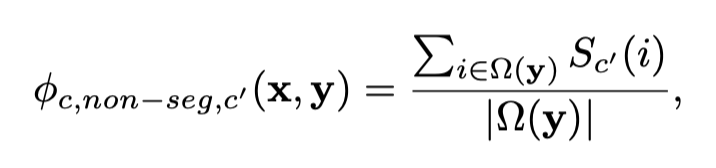
이 식들은 bounding box안에 다른 class에 해당하는 pixel의 비율을 minimize합니다.
shape
이 feature는 object의 shape을
This feature captures the shape of the objects.
We first compute the contour(윤곽선) in the output of the segmentation.
Create two grids for the 2D candidate box, one containing only a single cell, one that has KxK cells.
This potential tries to place a bounding box tightly around the object. encouraging the spatial distribution of contours within its grid to match the expected shape of a specific class.
Instance segmentation
We exploit instance level segmentation features, which score the amount of segment inside the box and outside the box.
This feature helps us to detect objects that are occluded as they form differnt instance.
context
This feature encodes the presence of contextual labels.
2D projection box 밑에 직사각형(위의 박스와 같은 width, 1/3 height를 갖는) 를 contextual region으로 설정한다.
contextual region 안에서 semantic segmentation feature을 계산한다.
location
This feature encodes a location prior of objects in both birds-eye perspective as well as in the image plane.
Kernel density estimation(KDE)(fixed standard deviation of 4m for 3D prior, 2pixels for the image domain)을 통해 prior을 학습한다.
3D prior는 3D ground truth bounding box를 통해 학습한다.
-3D Proposal Learning and Inference
we use exhaustive search(brute-force search) as inference to create our candidate proposals.
we learn the weights of the model using structured SVM.
we use the parallel cutting plane implementation of [40].
we use 3D Intersection-over-Union(IoU) as our task loss
-CNN Scoring of Top Proposals
이 절에서는, CNN을 통해 top candidates regions(NMS 적용 이후)의 점수를 매기는 방법을 소개한다.
CNN의 구조는 Fast R-CNN의 구조를 이용하여 설계하였다. ( 이 논문 저자의 NIPS 논문에서 사용한 네트워크 구조와 같은 구조를 사용하였다.) 네트워크 구조는 아래의 그림과 같다.

convolution layer를 지난후 두개의 branch로 나누어진다. 하나의 branch에서는 box proposal region을, 나머지 branch는 context region을 feature map에 projection하여 ROI pooling 을 적용하고 두개의 fully-connected layer 연산을 적용한다. (context region은 proposal regions을 1.5배 키운것)
연산을 통해 얻은 feature vector을 concatenate한 후 multi-task loss를 적용하여 category, bounding box off sets, object orientation을 prediction한다.
category loss는 cross entropy, orientation loss는 smooth L1, bounding box offset loss 는 smooth L1으로 적용한다.
-Implementation Details
Sampling Strategy
물체가 주로 ground plane 있을 것이라는 가정을 통해 sampling strategy를 정하였다.
In particular, we fix the normal of the plane and set height to hcam = 1.65 + δ. We set δ ∈ {0,±σ} for Car and δ ∈ {0,±σ ± 2σ} for Pedes- trian and Cyclist, where σ is the MLE estimate of the stan- dard deviation by assuming a Gaussian distribution of the distance from the objects to the default ground plane.
We use more planes for Pedestrian and Cyclist as small objects are more sensitive to errors. We further reduce the number of sampled boxes by removing boxes inside which all pixels were labeled as road, and those with very low prior proba- bility of 3D location. This results in around 14K candidate boxes per ground plane, template and per image.
이 sampling strategy를 통해 candidate box를 28% 줄였고, 이로인해 inference time을 상당히 줄였다고 한다.
Network Setup
VGG16을 통해 본 논문에서 제시한 네트워크의 파라미터들을 initialize하였다.
KITTI images의 작은 물체들을 잘 detection하기위해 input 이미지를 3.5배 upscale하였다. -> (논문에서는 이를 crucial to achieve very good preformance 라고 평가하였다.)
Experimental Evaluation
실험결과에 대해서는 생략!
Conclusion
we have proposed an energy minimization approach that places object candidates in 3D using the fact that objects should be on the ground-plane, and then scores each candidate box via several intuitive potentials encoding semantic segmentation, contextual information, size and lo- cation priors and typical object shape.
아직 이 논문에서 사용했다는 ground-plane에 대한 내용을 이해하지 못하였다.
에너지 식을 통해 scoring한 후 NMS로 걸러내고, 걸러낸 애들을 cnn을통해 다시한번 scoring?? 이런 pipeline이 맞나??
'3D Object Detection 논문' 카테고리의 다른 글
| PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection 리뷰 및 정리 (0) | 2021.02.11 |
|---|---|
| 3DVP: Data-Driven 3D Voxel Patterns for Object Category Recognition 리뷰 - 미완... (0) | 2021.01.27 |